![]()
![]()
Materials

You can find the workshop materials here.
Note: These materials are based on my learnings at NATCOR Taught Course Centre: Stochastic Modelling Course.
System states: weather example
We are interested in the transitions between different states. Suppose there are only 3 possible states in weather:
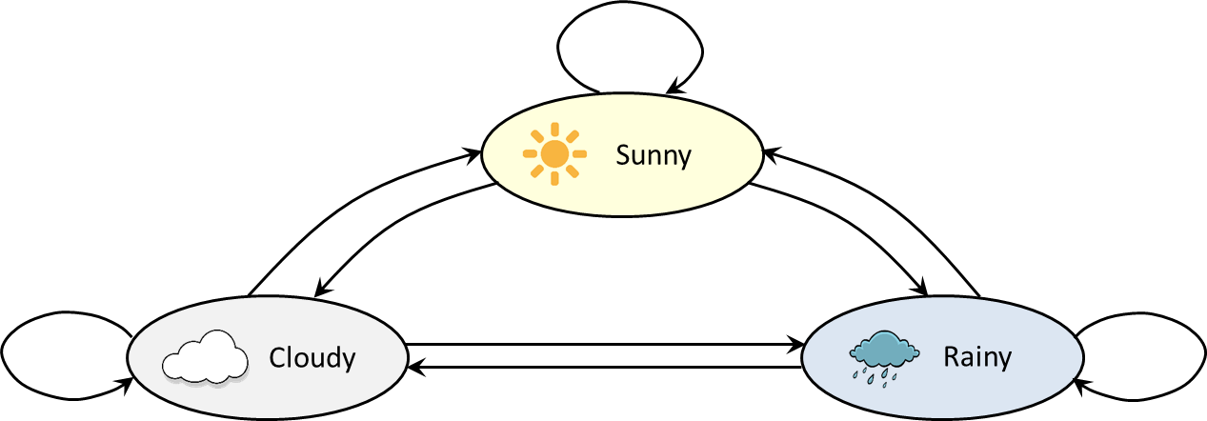
From any of the 3 states we can get to any of the other states in a single transition (or stay in the same state). A sample trajectory of the system could be:
\([Sunny, Cloudy, Cloudy, Rainy, Sunny, Cloudy, Rainy, Rainy, …]\)
System states: weather example cont.
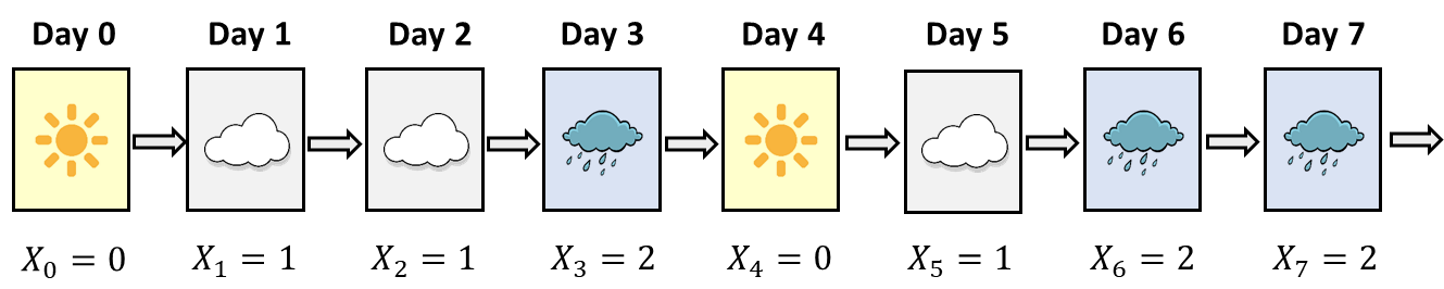
For convenience, let’s give each of the 3 states a number: \(0 – Sunny\), \(1 – Cloudy\), \(2 – Rainy\)
Let \(S\) be the set of system states. So in our example: \(S = {0, 1, 2}\)
Let \(X_n\) be the state of the system after \(n\) time units (e.g. days).
For example:
What is a good example of a Markov chain?
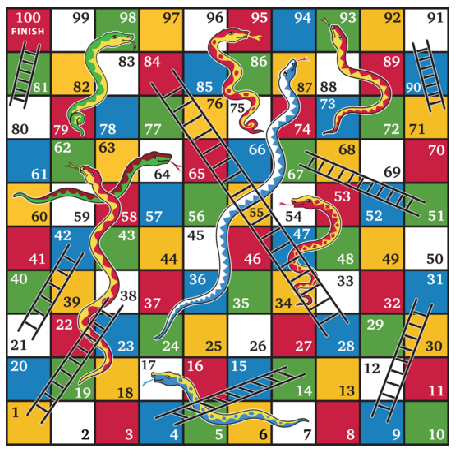
For example, in Snakes and Ladders,
if \(X_n = 50\) then:
- \(\displaystyle \Pr\bigl(X_{n+1}=67 \mid X_n=50\bigr) = \tfrac{1}{6}\)
- \(\displaystyle \Pr\bigl(X_{n+1}=52 \mid X_n=50\bigr) = \tfrac{1}{6}\)
- \(\displaystyle \Pr\bigl(X_{n+1}=53 \mid X_n=50\bigr) = \tfrac{1}{6}\)
- \(\displaystyle \Pr\bigl(X_{n+1}=34 \mid X_n=50\bigr) = \tfrac{1}{6}\)
- \(\displaystyle \Pr\bigl(X_{n+1}=55 \mid X_n=50\bigr) = \tfrac{1}{6}\)
- \(\displaystyle \Pr\bigl(X_{n+1}=56 \mid X_n=50\bigr) = \tfrac{1}{6}\)
Classifying states: infinitely many states
Suppose we have a Markov chain defined on the infinite state space \({0, 1, 2, …}\). If it is in state 0 then it moves to state \(1\) with probability \(1\). If it is in any other state then it moves up with probability \(p\) and moves down with probability \(1-p\), where \(0<p<1\).

Key point: if a Markov chain has infinitely many states, a steady-state distribution might not exist.
Classifying states: periodic states
Suppose we have a Markov chain which just goes back and forth between states 1 and 2. We call this a periodic Markov chain with a period of 2, because it can only return to the same state after an even number of time steps.
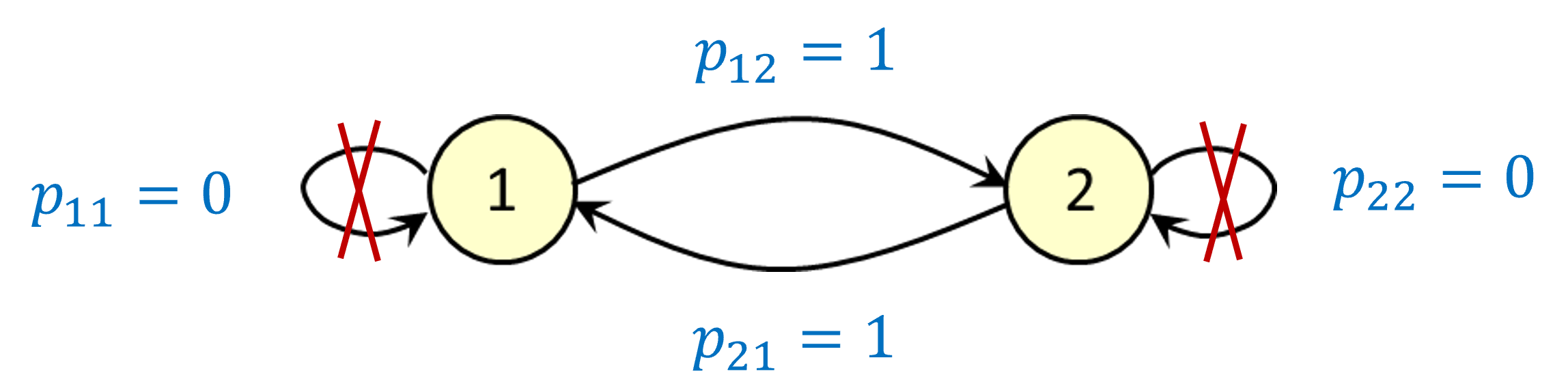
Key point: even if a steady-state distribution exists, the Markov chain might not “converge” to the steady-state distribution unless it actually starts there.
Classifying states: absorbing states
This time, we assume that if you’re in state 1 you stay there forever – and the same applies to state 2. In this case we call states 1 and 2 absorbing states.
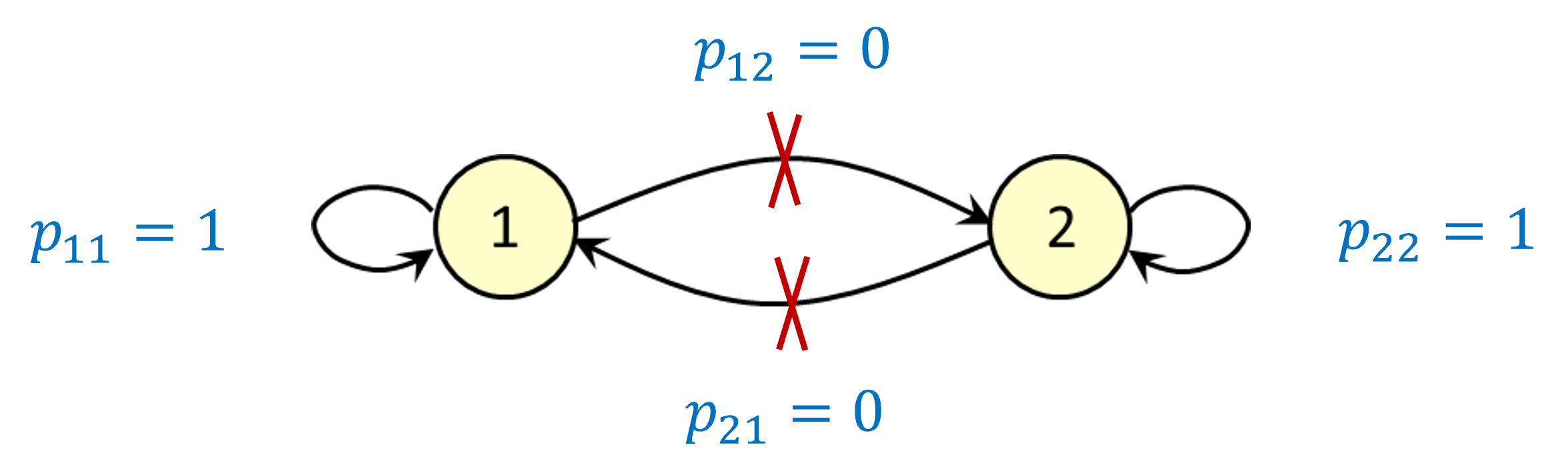
Key point: if states do not all “communicate” with each other (meaning that you cannot necessarily find a path from one state to another), there could be multiple steady-state distributions.
Lets promote Brand A cont.
We can represent this situation using a discrete-time Markov chain:
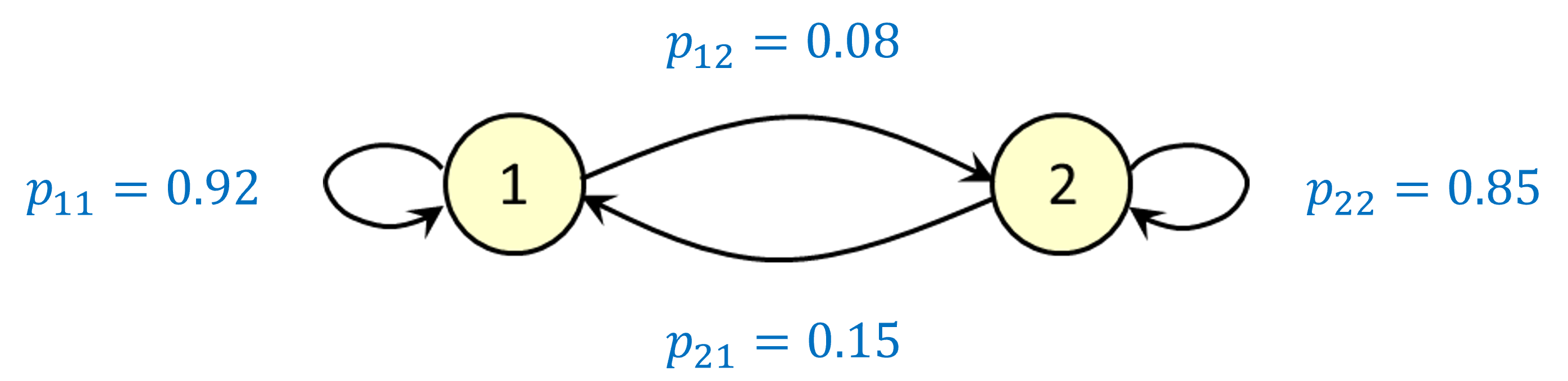
We are using some shorthand notation: \(p_{ij} = Pr(X_{n+1} = j \,|\, X_n = i)\)
Lets promote Brand A cont.
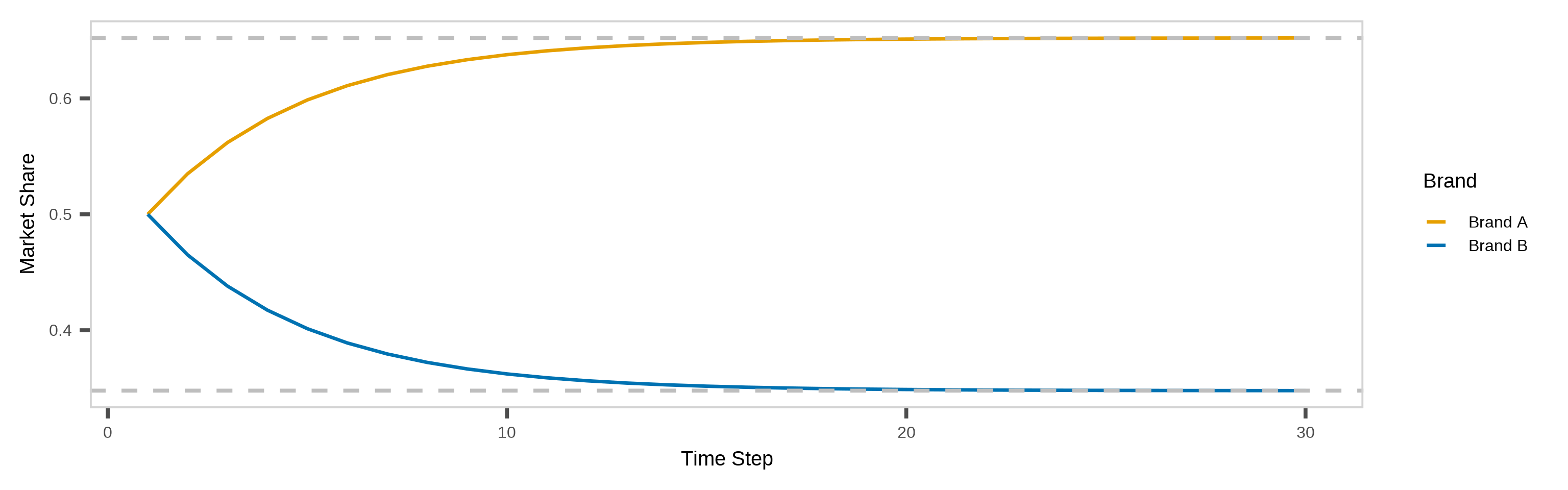
If we use a line graph to show how the expected market shares change with time, we find that both of them appear to converge to fixed values.
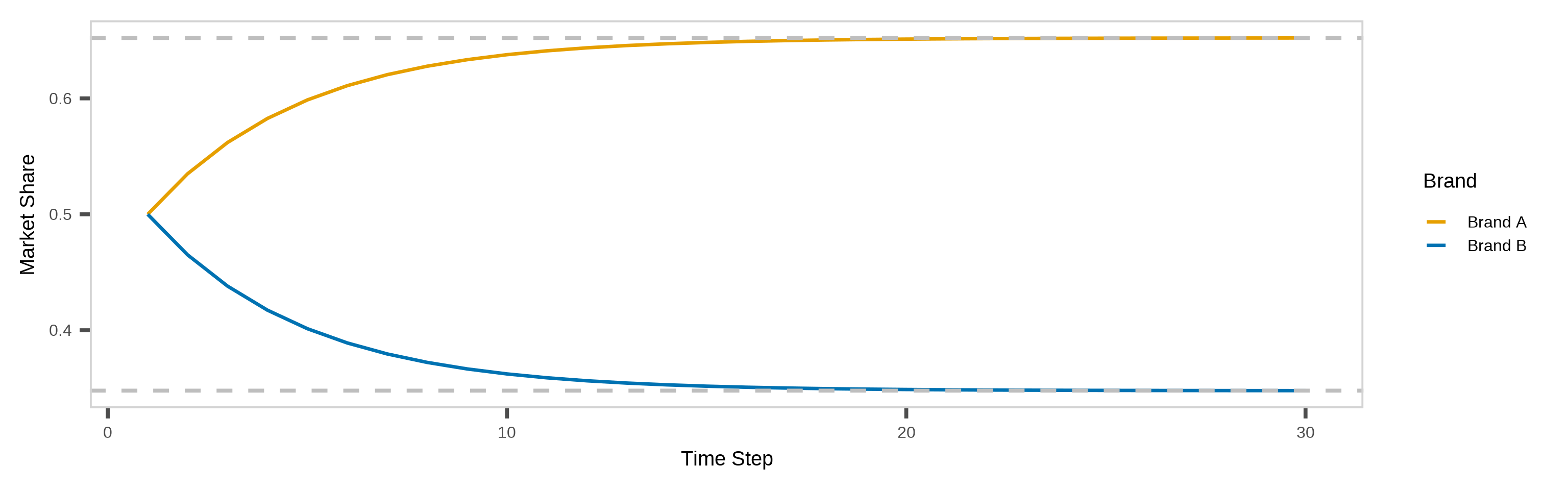
The market share for Brand A converges to about 65.2%, and the market share for Brand B converges to about 34.8%. We call (0.652, 0.348) the steady-state distribution in this example.
Lets promote Brand A cont.
Changing the initial probability vector \(\mathbf{q}^{(0)}\) has no effect on the steady-state distribution.