A Practical Guide to Model-Based, Bootstrap, and Conformal Prediction in R
Harsha Halgamuwe Hewage
Data Lab for Social Good Research Group, Cardiff University UK
2026/02/25
What we will cover
Why point forecasts fail and the necessity of quantifying risk
Model-Based Approaches: Using standard deviations and parametric assumptions
Bootstrapping: Generating sample paths to simulate complex, non-normal risks and “possible futures”
Conformal Prediction: Using calibration sets to create model-agnostic intervals with statistical guarantees
Comparative guide on picking the right method for your specific data challenges
Assumptions
Technical Setup: You must have R and RStudio installed and be comfortable with basic coding syntax.
Version Control: You should be able to use git to clone the workshop repository.
No Proofs: This is not a theory-based course, we will not derive formulas or mathematical proofs for convergence.
Practical Focus: Our goal is applied Uncertainty Quantification: understanding when to use specific tools to assess risk effectively.
What we will not cover
Deep Theory: Detailed mathematical derivations or proofs of coverage guarantees.
Different Distributions: Deep dives into specific distribution types (e.g., Poisson, Negative Binomial) beyond the fundamental Normal vs. Empirical distinction.
Advanced Variants: We will not cover complex variations like Sieve Bootstrap or Adaptive Conformal Inference in depth.
Model Tuning: We assume you can fit a basic model; we focus strictly on quantifying the errors of that model.
Performance Evaluation: In this session, we will not cover how to evaluate probabilistic forecasts.
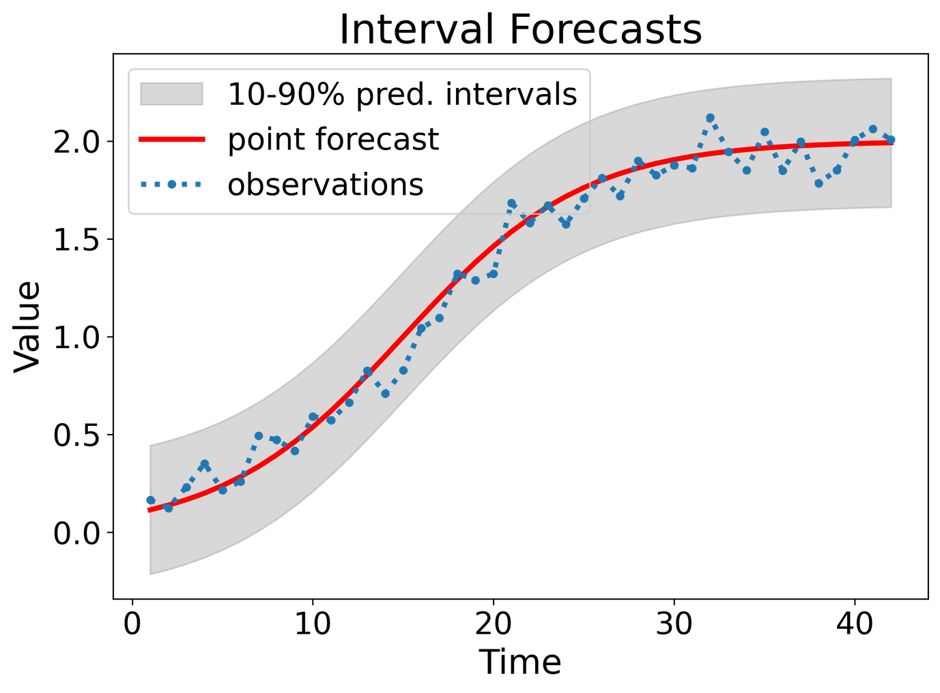
A point forecast is typically just the mean or median of a distribution.
In public health, the cost of being wrong is not symmetrical.
Over-estimating cases might waste some supplies or under-estimating cases (missing an outbreak) costs lives.
Point forecasts are of almost no value without accompanying prediction intervals because they tell you nothing about the probability of exceeding critical thresholds.
From “Will it happen?” to “What is the probability?”
We move from guessing a specific number to defining a range (e.g., 90% likely to fall between 100 and 500 cases).
Climate data (rainfall, temperature) is inherently noisy and non-stationary.
As climate volatility increases, the uncertainty in our disease models expands.
We do not prepare for the mean scenario; we prepare for the extreme scenario. Uncertainty quantification allows us to ask: What is the probability we exceed hospital bed capacity?
Moving from “What is the number?” to “What is the risk?” using uncertainty quantification.
Types of uncertainty output
Distributions
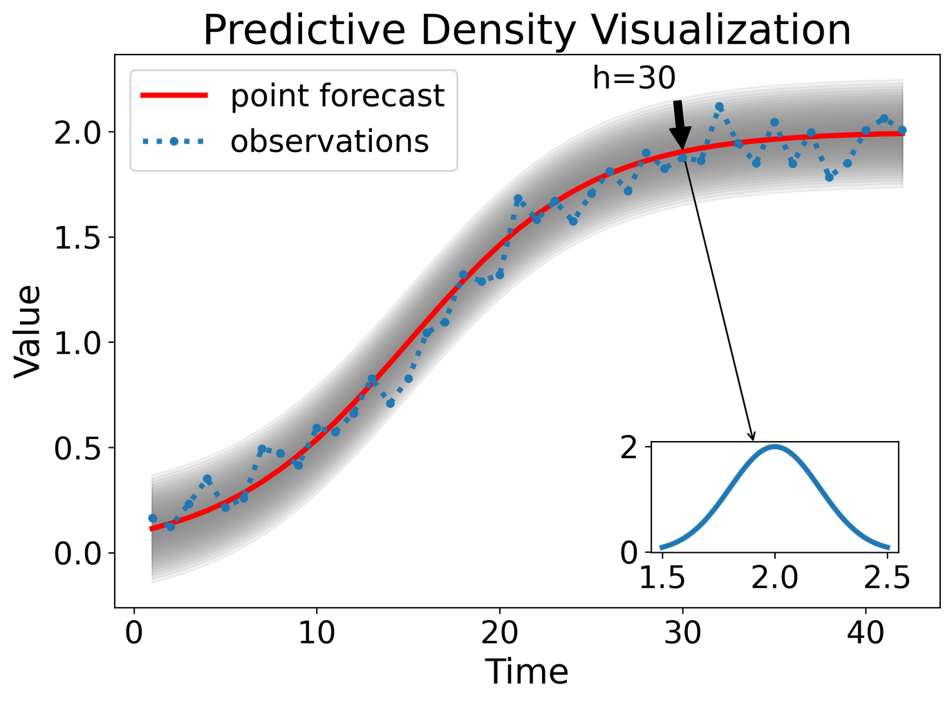
The full range of possible future case counts, capturing the full range of potential outcomes across all time horizons. The point forecast is just the “typical” outcome.
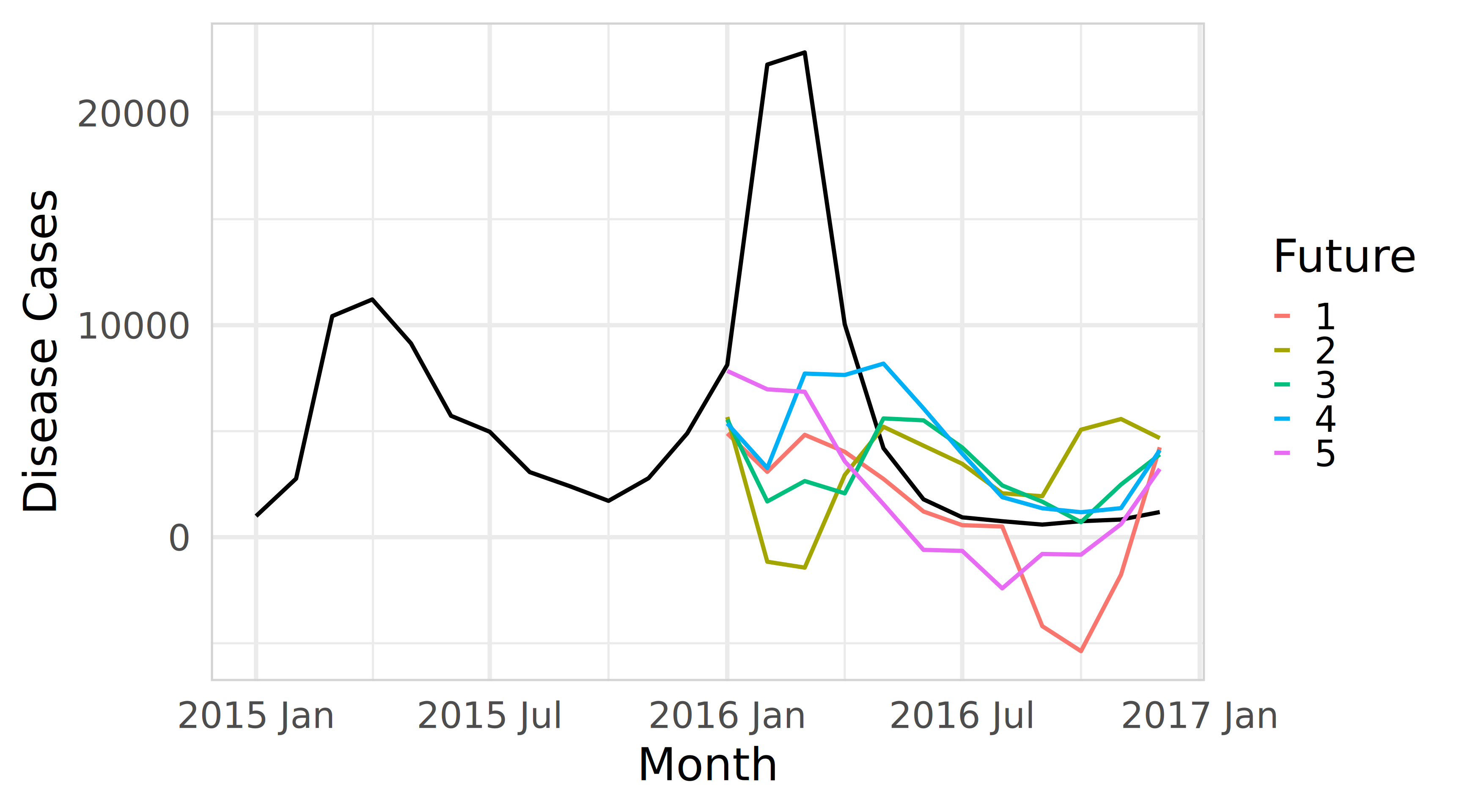
Sample Paths
Many simulated “possible futures” that help you see what could happen and summarize risk for totals, peaks, or other real-world planning questions.
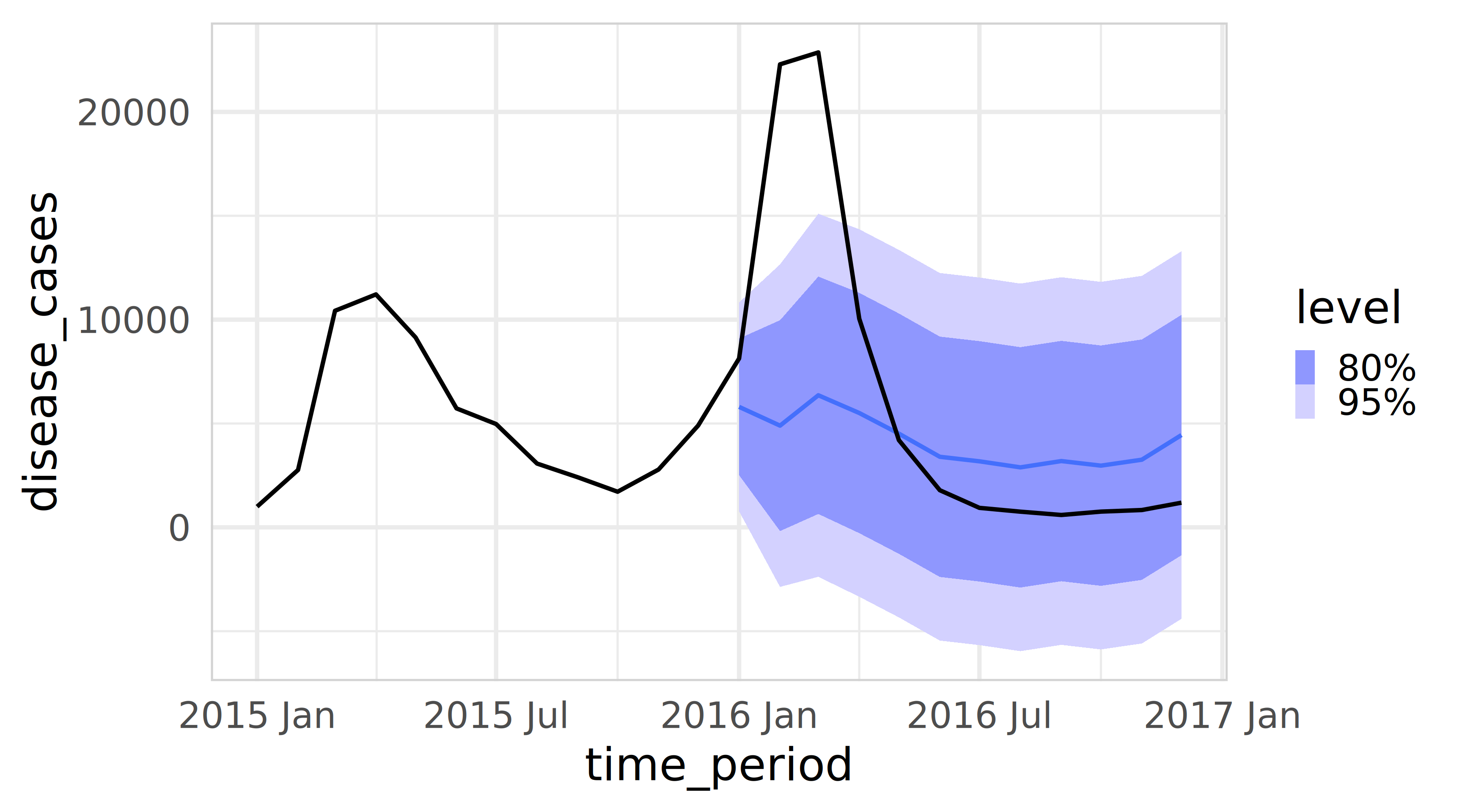
Prediction Intervals
A range (e.g., 95%) that shows where cases are likely to fall, helping you plan for high-demand scenarios, not just the average.
Uncertainty estimation in forecasting
Model-based Approaches
Examples: ARIMA/state-space models
Assumption: Explicit parametric error distribution
Model-agnostic Approaches
Bootstrap: Residual bootstrap, block bootstrap
Conformal predictions
Bayesian Approaches
Bayesian: Posterior predictive distribution
Depend on prior / resampling scheme
Model-dependent / Heuristic Approaches
Quantile regression, ML-based quantile models
Heuristic ML: Ensembles, MC dropout
Uncertainty estimation in forecasting
Model-based Approaches
Examples: ARIMA/state-space models
Assumption: Explicit parametric error distribution
Model-agnostic Approaches
Bootstrap: Residual bootstrap, block bootstrap
Conformal predictions
Bayesian Approaches
Bayesian: Posterior predictive distribution
Depend on prior / resampling scheme
Model-dependent / Heuristic Approaches
Quantile regression, ML-based quantile models
Heuristic ML: Ensembles, MC dropout
01
Model-based approaches using ARIMAX
Forecast distributions
In model-based approaches, we do not simulate future paths one by one. Instead, we assume that the forecast errors (residuals) follow a specific probability distribution.
A forecast \(\hat{y}_{T+h \mid T}\) is (usually) the mean of the conditional distribution \(y_{T+h} \mid y_{1}, \ldots, y_{T}\).
Most time series models produce normally (i.e., Gaussian) distributed forecasts.
The forecast distribution describes the probability of observing any future value.
The model estimates the “center” (point forecast) and the “spread” (standard deviation) mathematically.
The Center (\(\hat{y}\)): The mean of the distribution.
The Spread (\(\sigma_h\)): The standard deviation of the forecast errors at horizon \(h\).
Normality: The forecast errors (residuals) follow a symmetric Bell Curve.
Uncorrelated: The model has captured all signal; the remaining errors have no pattern (white noise).
Homoscedasticity: The volatility (variance) of errors is constant over time and does not explode during specific seasons.
Best for: Stable, high-volume data where you need a quick, standard answer.
Pros
Cons
When to Select
Speed & Standardization: Instant calculation using analytic formulas (e.g., \(\pm 1.96\sigma\)). It is the default output in almost all software, making it easy to reproduce and audit.
Symmetry Assumption: Assumes errors are symmetric. For low disease counts, this often produces physically impossible negative lower bounds.
High-Volume Data: When case counts are high (e.g., >100/month) and the distribution looks roughly Bell-shaped.
Stability: Performs reliably on data that is consistent, has a long history, and follows standard seasonal patterns.
Underestimated Risk: Often too narrow because it ignores parameter uncertainty (the risk that the model parameters themselves are slightly wrong).
Short Horizons: For 1-step ahead forecasts where the “fan” of uncertainty hasn’t had time to compound or break down.
Simplicity: Easy to explain to stakeholders as a “standard statistical range.”
Tail Sensitivity: If the data has “fat tails” (extreme outbreaks), the Normality assumption fails, and a 95% interval will not actually cover 95% of events.
Establishing a Baseline: Use this first to set a benchmark. If complex methods don’t beat this, stick with this.
02
Bootstrapping time series
Forecast sample paths (Bootstrapping)
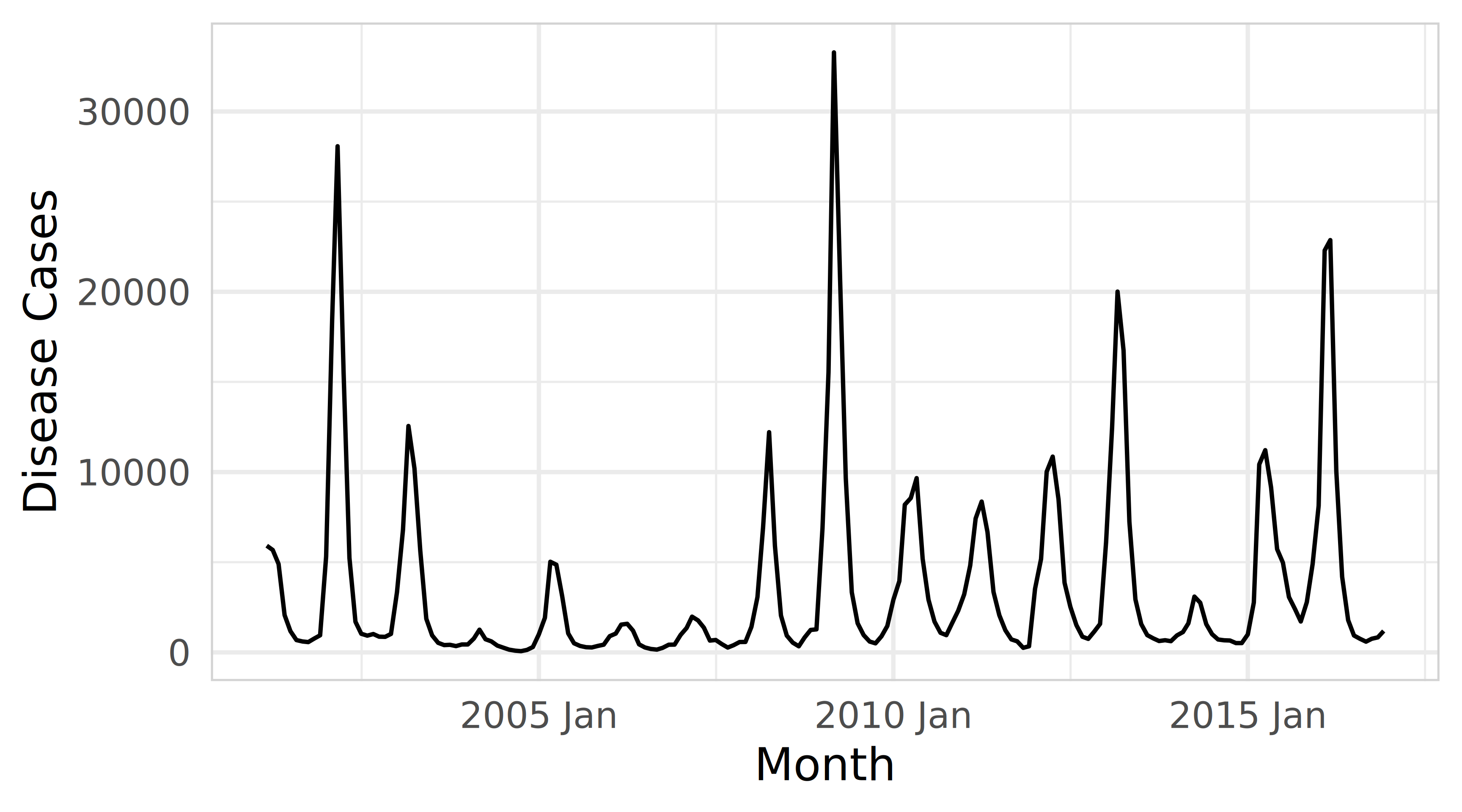
When a Normal distribution for the residuals is an unreasonable assumption (e.g., extreme outbreaks, skewed data), we use bootstrapping. This assumes that “future errors will look like past errors”.
Instead of using a fixed formula, we simulate \(B\) different “possible futures” (sample paths) by randomly sampling from past residuals.
Resample: Take a random error (\(e^*\)) from the past.
Representativeness: The past residuals are a good sample of what could happen in the future.
Independence (Standard): Residuals are uncorrelated (IID).
Independence (Block): If residuals are dependent (autocorrelated), we must sample “blocks” of errors rather than single points to preserve the structure.
Best for: “What-if” scenarios, cumulative risk, and explosive outbreaks.
Pros
Cons
When to Select
Captures Asymmetry: Does not force a Bell Curve. It naturally handles skewed risk (e.g., cases can spike to 5,000 but cannot go below zero).
Computationally Expensive: Slower than model-based methods; requires generating and storing 1,000+ sample paths per series.
Explosive Outbreaks: When the risk is one-sided (e.g., a potential exponential spike in Dengue cases).
Path Dependency: Simulates connected trajectories. This allows you to calculate cumulative risk (e.g., “Probability that cases exceed capacity for 3 weeks in a row”).
The Autocorrelation Trap: Standard bootstrapping destroys temporal patterns. If residuals are dependent (sticky), you must use “Block Bootstrap,” which adds complexity.
Cumulative Risk Analysis: When stakeholders need to know the total case count over the next season, not just the peak.
Robustness: Works well when residuals have extreme outliers or “fat tails” that would break a normal distribution.
Data Hungry: Requires a long enough history of residuals to draw a representative sample.
Low Count Data: When a standard model is predicting negative numbers and you need a strict zero-bound.
03
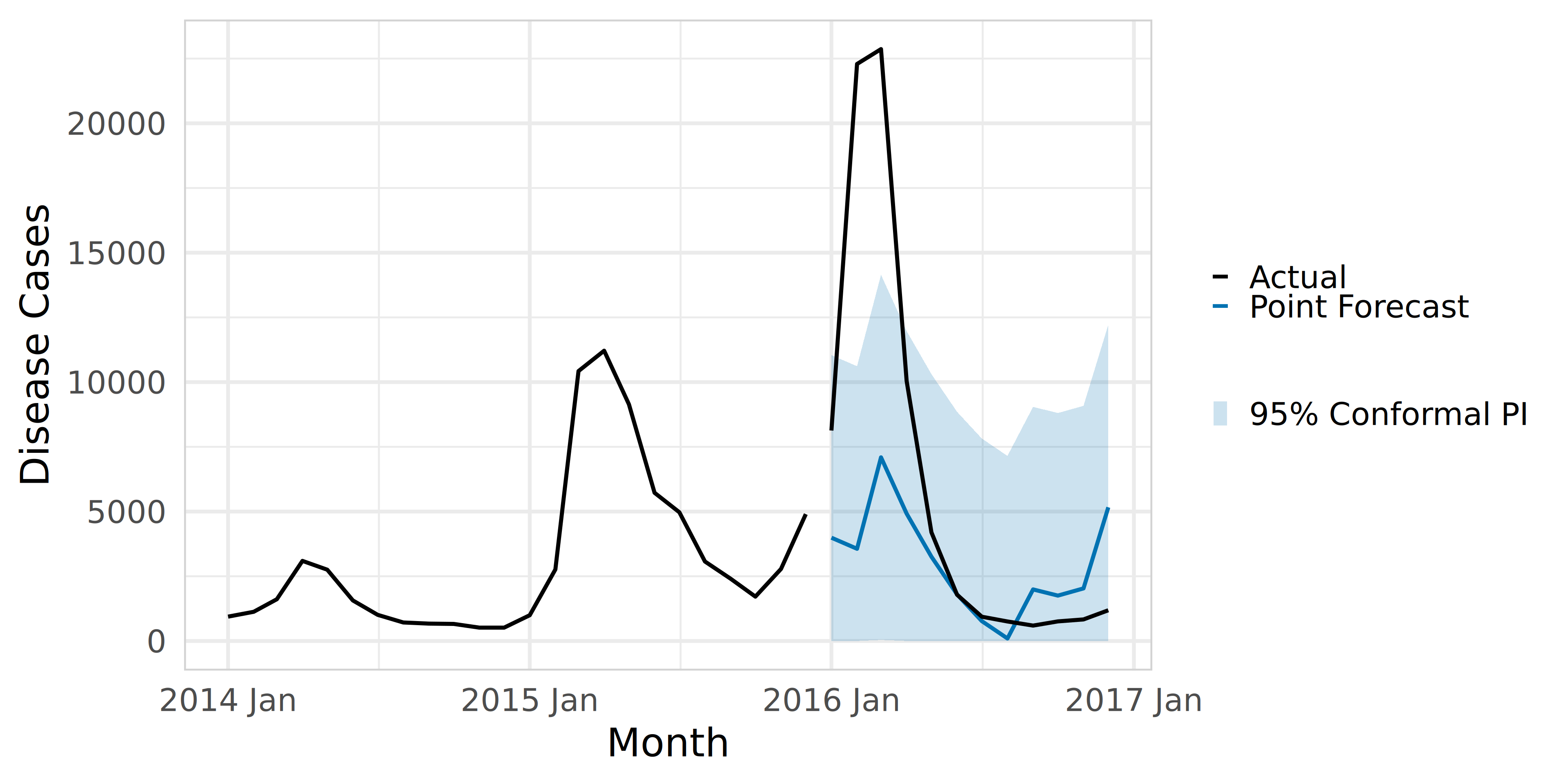
Conformal predictions
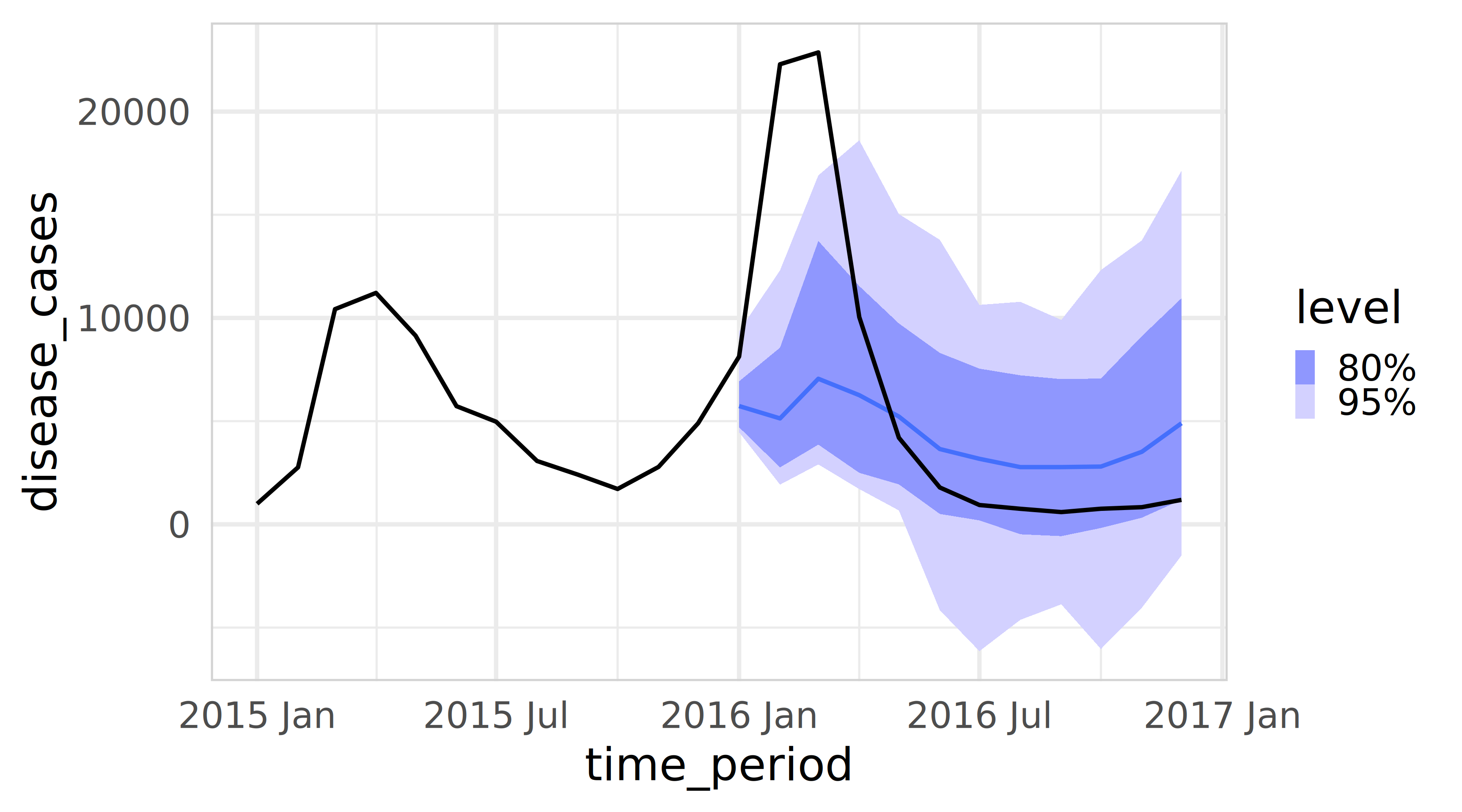
Conformal prediction intervals
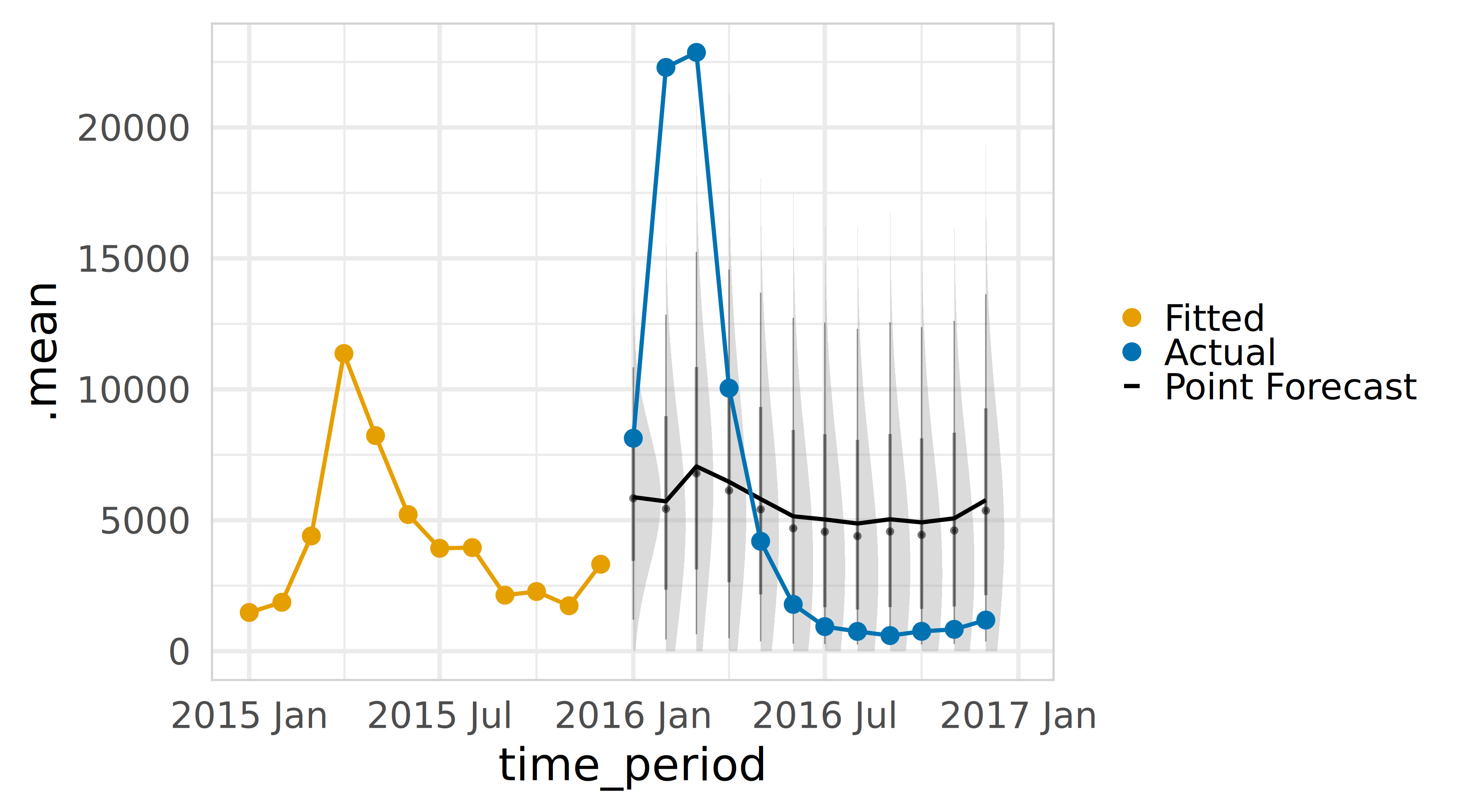
Unlike Model-Based methods (which assume a distribution) or Bootstrapping (which assumes history repeats), Conformal Prediction focuses on the model’s past performance on unseen data. It asks: “How wrong was this model on the calibration set?” and uses that to build a rigorous interval for the future.
Train point forecast model on the training set and forecast on calibration set
Get conformity scores and create a sorted list with absolute conformity scores
Select the quantile of the prediction interval
Conformal prediction intervals
Unlike Model-Based methods (which assume a distribution) or Bootstrapping (which assumes history repeats), Conformal Prediction focuses on the model’s past performance on unseen data. It asks: “How wrong was this model on the calibration set?” and uses that to build a rigorous interval for the future.
Forecast with a point forecast model
Add prediction interval based on conformity scores
Conformal prediciton using ConformalForecast in R
Pick one series and prepare data
Code
bahia <- brazil_dengue_tsb |>filter(location =="Bahia") |>arrange(time_period) |>as_tibble()y_all <-ts(bahia$disease_cases, frequency =12)xreg_all <- bahia |>select(rainfall, mean_temperature) |>as.matrix()# Define split datestrain_end <-yearmonth("2014 Dec")calib_start <-yearmonth("2015 Jan")calib_end <-yearmonth("2015 Dec")test_start <-yearmonth("2016 Jan")test_end <-yearmonth("2016 Dec")idx <- bahia$time_periodi_train_end <-max(which(idx <= train_end))i_calib_end <-max(which(idx <= calib_end))i_test_start <-min(which(idx >= test_start))i_test_end <-max(which(idx <= test_end))# train length used as rolling window size in cvforecastwindow_len <- i_train_end# series up to end of calibration (train + calibration)y_train_calib <-ts(bahia$disease_cases[1:i_calib_end], frequency =12)xreg_train_calib <- xreg_all[1:i_calib_end, , drop =FALSE]
Create forecast function for cvforecast (ARIMAX via forecast::Arima)
Code
farimax_1step <-function(x, h, level) { t <-length(x) xreg_train <- xreg_train_calib[1:t, , drop =FALSE] xreg_future <- xreg_train_calib[(t +1):(t + h), , drop =FALSE] fit <- forecast::Arima(x, xreg = xreg_train) forecast::forecast(fit, h = h, level = level, xreg = xreg_future)}
“Calibration” residuals via cvforecast across the 12 calibration months
Code
# This produces 1-step-ahead errors for each month in the calibration year.fc_cal <-cvforecast(y = y_train_calib,forecastfun = farimax_1step,h =1,level =95,forward =FALSE,window = window_len,initial =1)# absolute errors (conformity scores)scores <-abs(as.numeric(fc_cal$ERROR))q_95 <-quantile(scores, 0.95, na.rm =TRUE)
Conformal prediciton using ConformalForecast in R
Forecast the 12-month test period (fit on train+calib, forecast test)
Code
# Fit on all available up to calibration end:fit_final <- forecast::Arima(ts(bahia$disease_cases[1:i_calib_end], frequency =12),xreg = xreg_all[1:i_calib_end, , drop =FALSE])fc_test <- forecast::forecast( fit_final,h = (i_test_end - i_test_start +1),xreg = xreg_all[i_test_start:i_test_end, , drop =FALSE])test_dates <- bahia$time_period[i_test_start:i_test_end]yhat <-as.numeric(fc_test$mean)
Exchangeability: The calibration data (recent past) looks statistically similar to the test data (near future).
Symmetry: Standard “Split Conformal” produces symmetric intervals (constant width), though advanced versions (CQR) can handle asymmetry.
Best for: Complex “Black Box” models (AI/ML) and strict policy requirements.
Pros
Cons
When to Select
Model Agnostic: Works with any model (Neural Networks, Random Forest, XGBoost). You do not need to understand the math inside the “black box”.
Data Hungry (Splitting): Requires a separate “Calibration Set” withheld from training. In short time series, sacrificing 20% of data for calibration is painful.
Using Machine Learning: When you are using complex non-linear models where calculating a standard deviation (\(\sigma\)) is impossible.
Finite-Sample Guarantee: Mathematically guaranteed to cover the true value \((1-\alpha)\%\) of the time, regardless of the underlying distribution.
The Drift Problem: Relies on “Exchangeability.” If the climate shifts effectively (Distribution Drift), the calibration data no longer represents the future, and coverage fails.
Regulatory/Policy Compliance: When you must prove to stakeholders that your intervals are statistically valid (e.g., “guaranteed 90% coverage”).
Distribution Free: Does not assume errors are Normal, Poisson, or Skewed. It constructs intervals based purely on empirical past performance.
Constant Widths: Basic Split Conformal produces a fixed-width “tube” that doesn’t adapt to local volatility (unless using advanced Adaptive Conformal).
Complex Distributions: When data is messy, multi-modal, or refuses to fit any standard statistical distribution.