| Method | Covariates |
|---|---|
| Auto EWARS | Population, rainfall, teamperature |
| INLA Baseline | None |
| Naïve | None |
| sNaive | None |
| Mean | None |
| ETS | None |
| ARIMA | None |
| ARIMA Climate | Rainfall, temperature |
| ARIMA Madagaskar | Rainfall (Lag 3), temperature (Lag 3) |
| Linear Regression | Trend, seasonality |
| Linear Regression Climate | Trend, seasonality, rainfall, teamperature |
| LightGBM | Percentage of zero values, lags of target variable (lag 6 - 12), rainfall, temperature, month, healthcare facility code, product code |
| XGBoost | Percentage of zero values, lags of target variable (lag 6 - 12), rainfall, temperature, month, healthcare facility code, product code |
| Random Forest | Percentage of zero values, lags of target variable (lag 6 - 12), rainfall, temperature, month, healthcare facility code, product code |
![]()
![]()

![]()


Outline
Background
The fundamental question
What we are going to do
What did we find
Live demo

The Problem: A tale of two data streams
Health supply chains are struggling with forecasting at sub-national/ facility level.
Operational realities: Incomplete records, irregular orders, frequent manual adjustments.
This masks true demand and leads to a cycle of persistent, critical stockouts.
But… we have a success story.
Platforms like DHIS2 and CHAP have robust, high-performing models for forecasting disease cases (morbidity).

What we are going to do
Apply the same CHAP morbidity models (no extra tuning) to product demand (malaria commodities, vaccines).
Link forecasts to operations: evaluate both forecast accuracy and inventory impact.
Build a portability matrix: when can we transfer a model?
Design an implementation workflow for DHIS2/CHAP.
Provide R scripts, CHAP YAML configs and sample datasets for full reproducibility.
Why forecasting is not “one AI model”
In practice, forecasting relies on many different types of models, each designed for different data patterns and decisions.

This is where CHAP within DHIS2 differs from AI agents: CHAP is model-agnostic. It lets users run, compare, and select models, rather than delegating all decisions to a single AI agent.
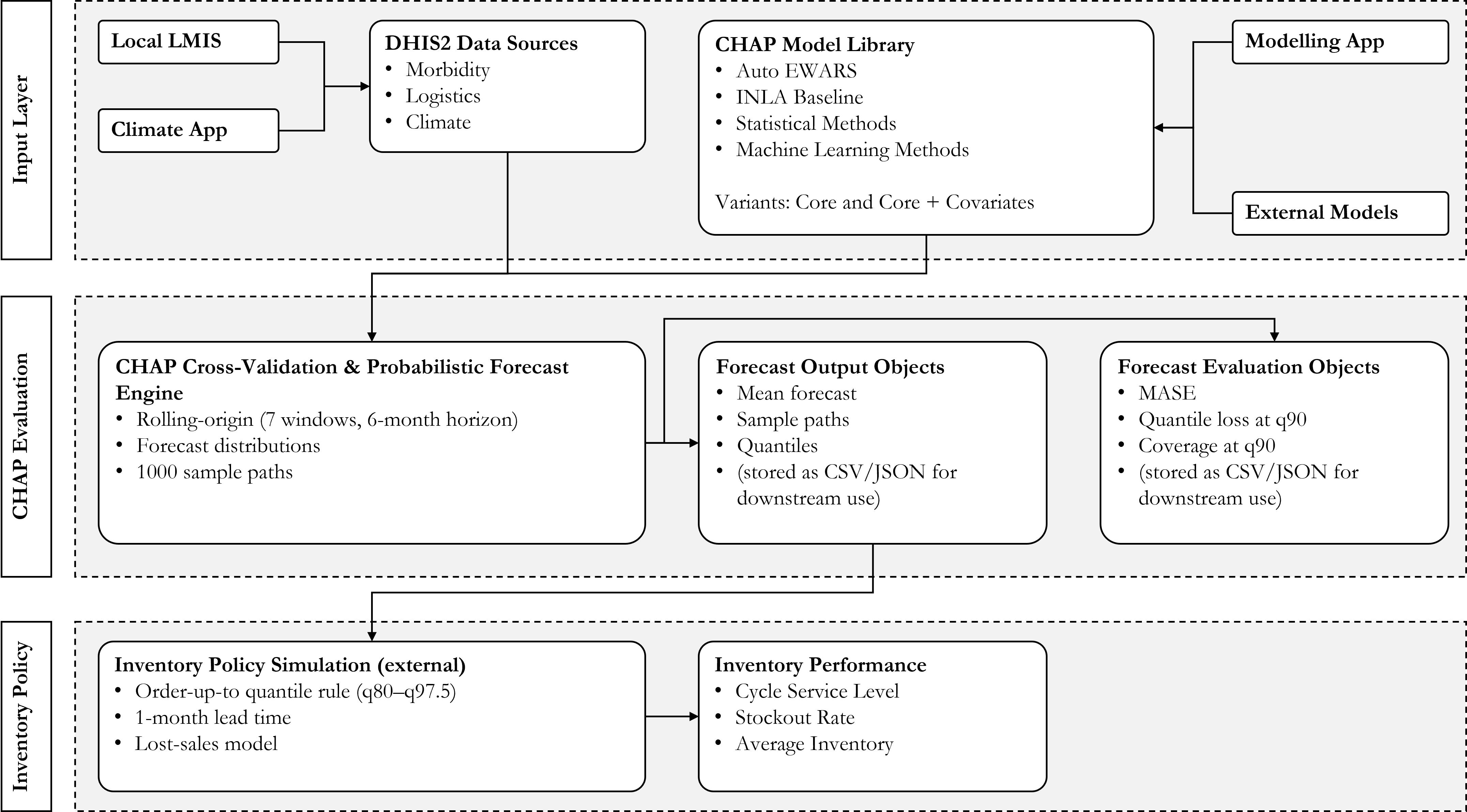
Our experimental workflow
Data exploration
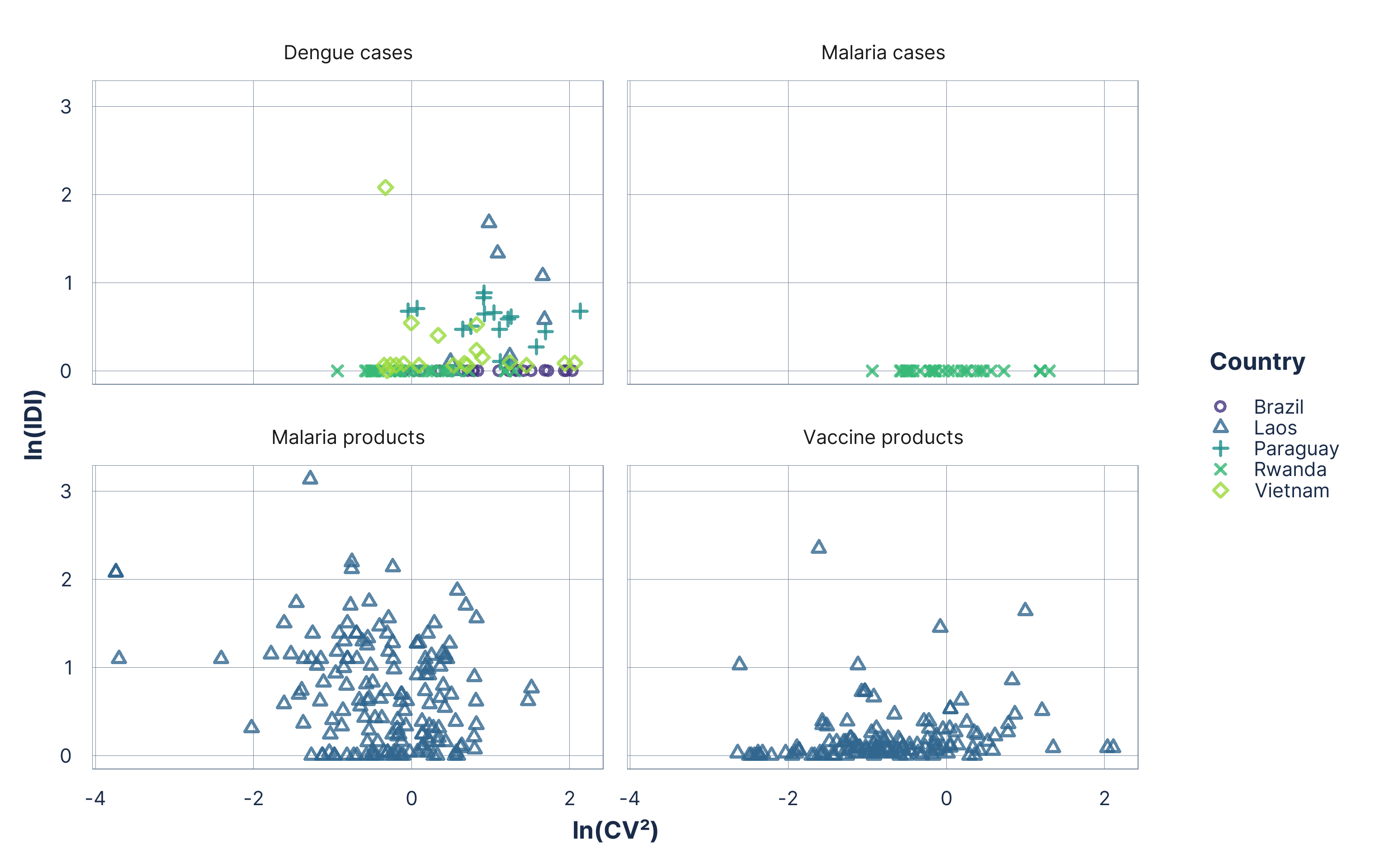
Figure 1: Classification of all morbidity and consumption series using the ln(CV²) and ln(IDI) map. Each point represents a monthly series plotted on the logarithmic CV²–IDI scale.
Average forecast method rankings
Figure 2: Average point forecast (MASE) ranks. Methods on the y-axis are ordered from best (top) to worst (bottom) based on their overall average rank across all domains. Lower ranks indicate better performance.
Average forecast method rankings
Figure 3: Average probabilistic forecast (quantile loss) ranks. Methods on the y-axis are ordered from best (top) to worst (bottom) based on their overall average rank across all domains. Lower ranks indicate better performance.
Overall inventory performance - Malaria products
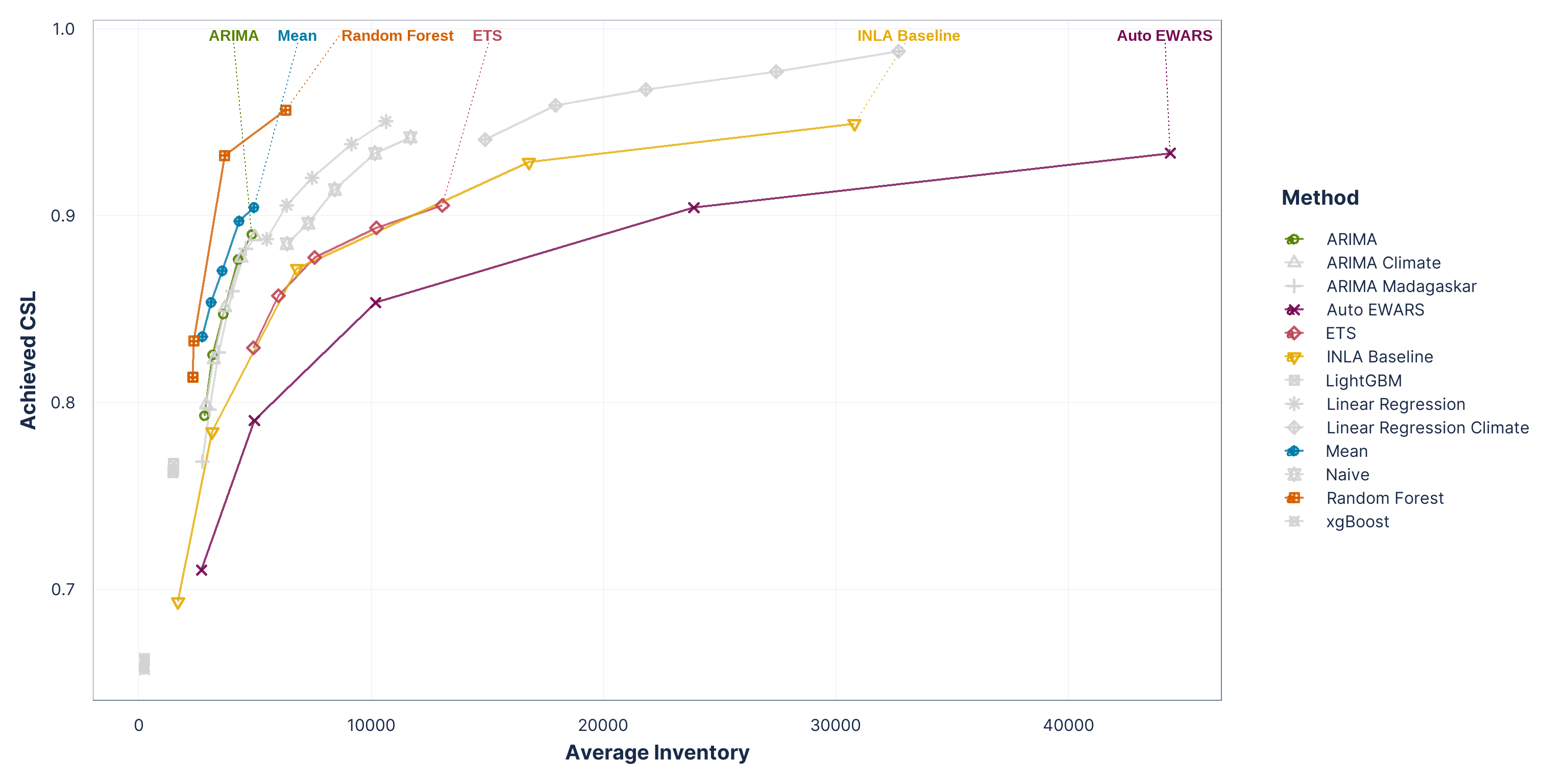
Figure 4: Inventory performance across malaria-product simulations using quantile-based order-up-to policies (q80–q97.5).
Overall inventory performance - Vaccine
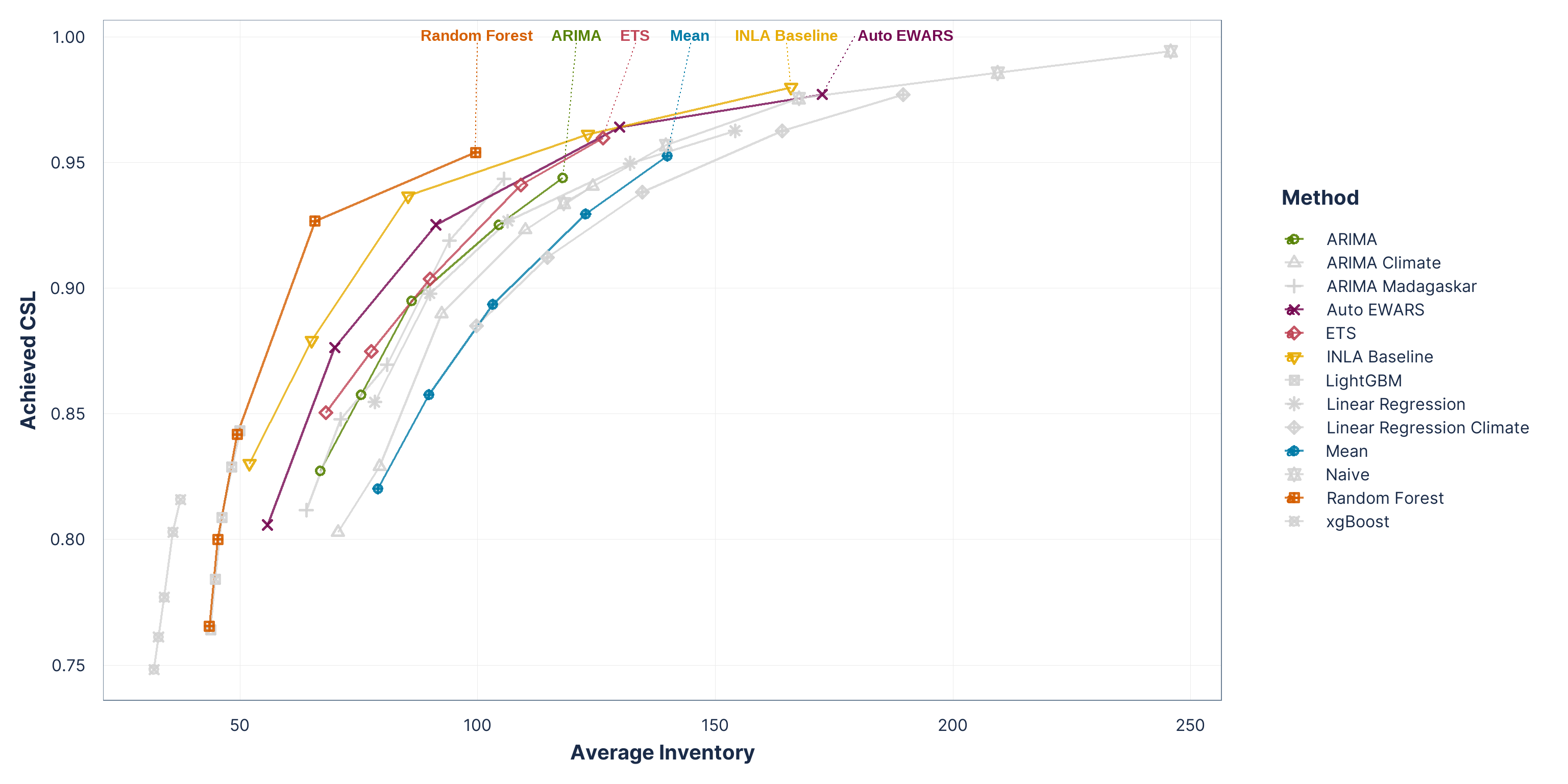
Figure 5: Inventory performance across vaccine-product simulations using quantile-based order-up-to policies (q80–q97.5).
Execution scalability of all forecasting methods
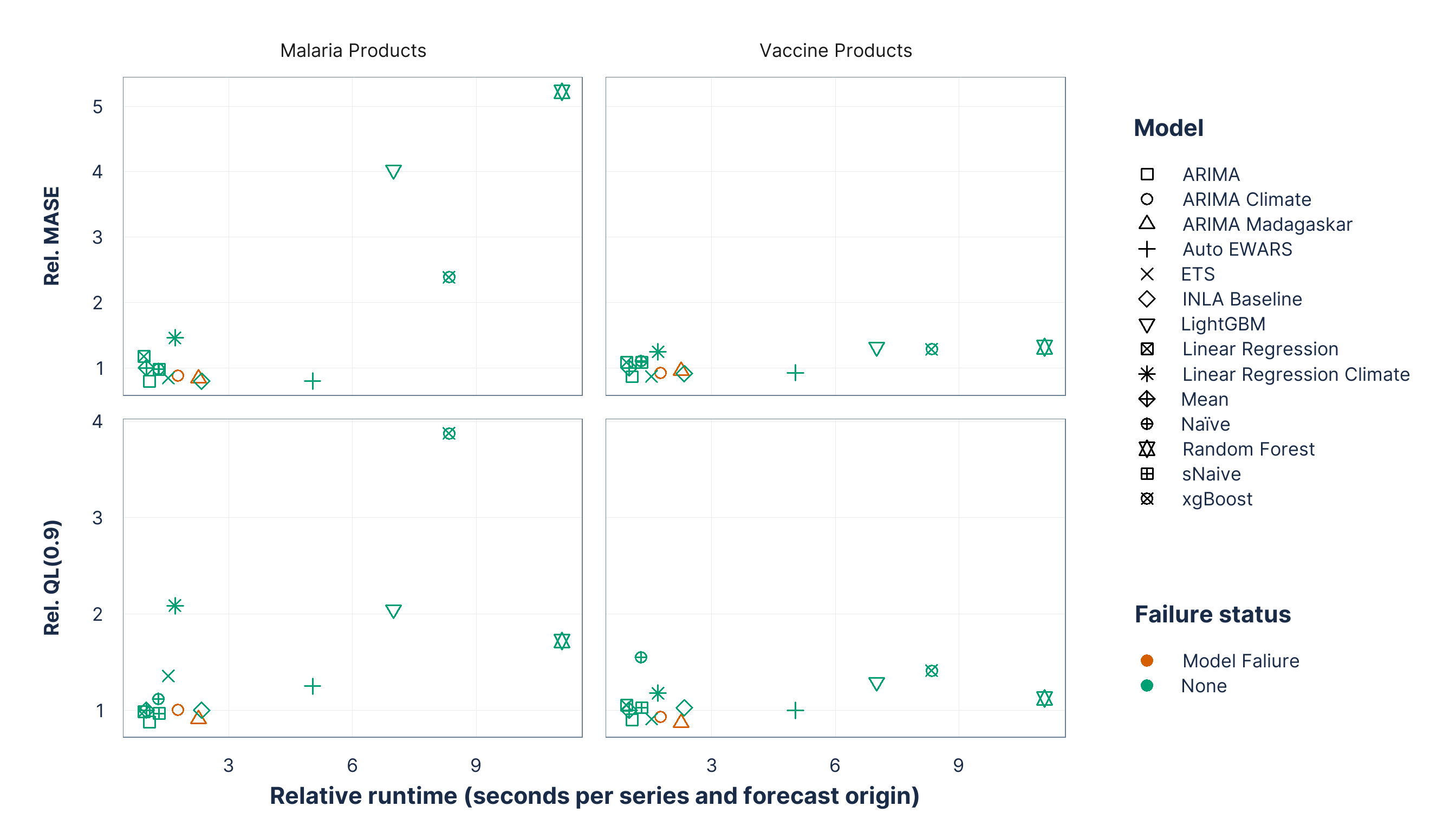
Figure 6: Model portability metrics for all candidate forecasting methods, relative to the Mean method. Relative MASE and QL(0.9) are reported separately for malaria and vaccine products; values below 1 indicate improvement over the Mean method.
Any questions or thoughts? 💬
